|
I am a Research Scientist at Google DeepMind working on personalization and reasoning in Project Astra and Gemini. I received my Ph.D. in EECS at MIT CSAIL advised by Professor Pulkit Agrawal where I worked on Offline RL, Generative Modeling and Foundation Models for Decision Making. Before that, I received my S.M. in EECS from MIT advised by Professor Leslie Kaelbling and Professor Josh Tenenbaum. Prior to joining MIT, I completed my bachelor's degree in EECS from UC Berkeley where I worked with Professor Pieter Abbeel and Professor Sergey Levine. I have also been fortunate to spend time at Meta AI (FAIR) and Google Brain. |

|
|
|
|
|
Arjun Majumdar*, Anurag Ajay*, Xiaohan Zhang*, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, Karmesh Yadav, Qiyang Li, Ben Newman, Mohit Sharma, Vincent Berges, Shiqi Zhang, Pulkit Agrawal, Yonatan Bisk, Dhruv Batra, Mrinal Kalakrishnan, Franziska Meier, Chris Paxton, Sasha Sax, Aravind Rajeswaran (* Equal Contribution) CVPR, 2024 ICRA Workshop on Mobile Manipulation and Embodied Intelligence, 2024 (Spotlight) paper / blog / bibtex / project page We introduce a modern formulation of Embodied Question Answering (EQA) accompanied by OpenEQA, the first open-vocabulary benchmark dataset for EQA, supporting episodic memory and active exploration use cases. We also provide an automatic LLM-powered evaluation protocol that correlates strongly with human judgment. We evaluate various foundation models, including GPT-4V, which show significant shortcomings compared to human performance. |
|
|
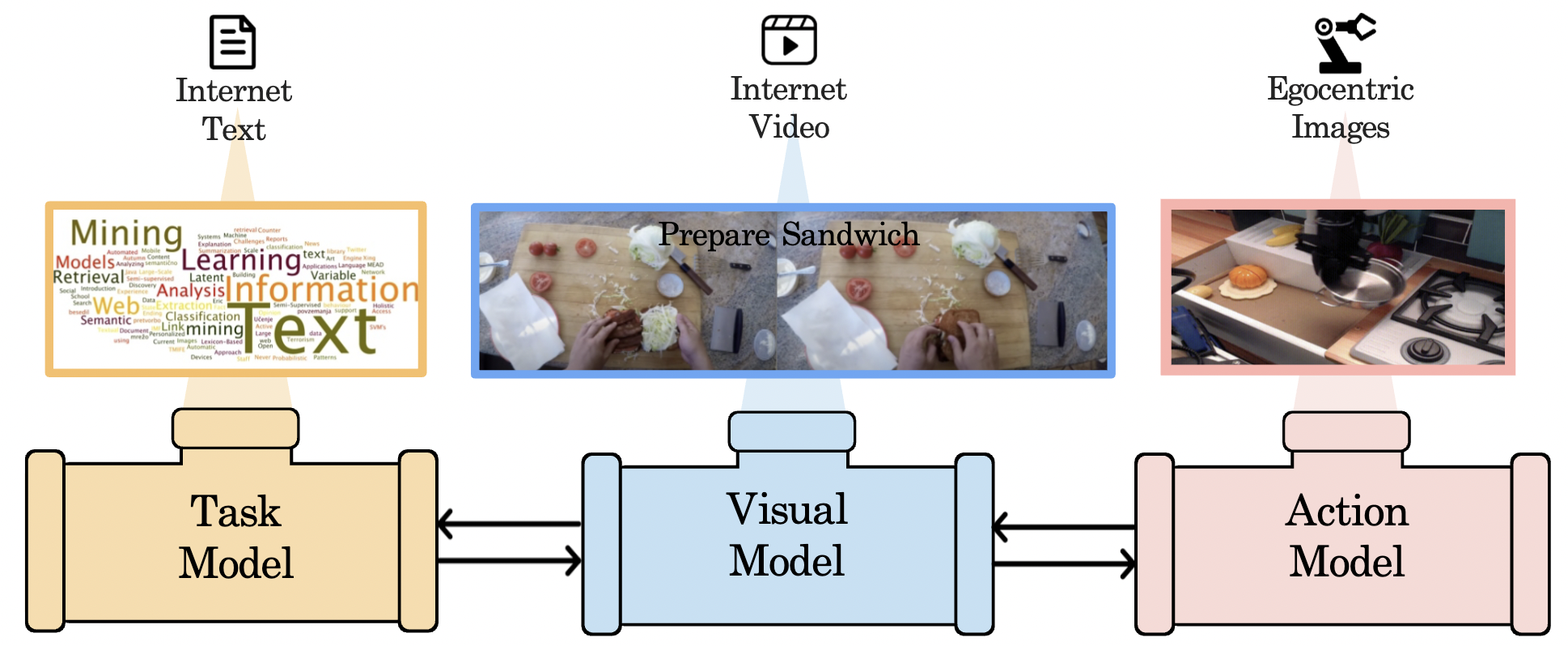
Anurag Ajay*, Seungwook Han*, Yilun Du*, Shuang Li, Abhi Gupta*, Tommi Jaakkola, Josh Tenenbaum, Leslie Kaelbling, Akash Srivastava, Pulkit Agrawal (* Equal Contribution) NeurIPS, 2023 arXiv / bibtex / project page We propose a foundation model which leverages multiple expert foundation model, each individually trained on language, vision and action data, jointly together to solve long-horizon tasks. We use a large language model to construct symbolic plans that are grounded in the environment through a large video diffusion model. Generated video plans are then grounded to visual-motor control, through an inverse dynamics model that infers actions from generated videos. |
|
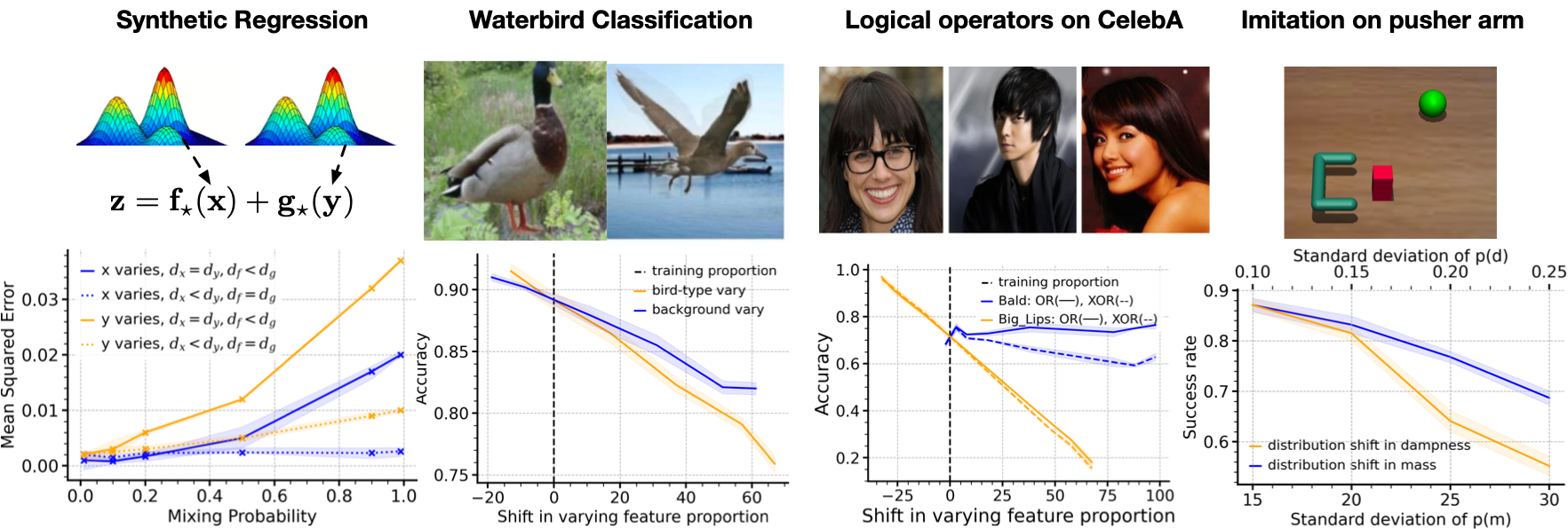
Max Simchowitz*, Anurag Ajay*, Pulkit Agrawal, Akshay Krishnamurthy (*Equal Contribution) ICML, 2023 arXiv / bibtex We analyze the interaction between a heterogeneous distribution and statistical complexity in a limited but still mathematically non-trivial setting and use this analysis to make principled predictions about which shifts we expect our models to be more or less resilient to: specifically, how to empirically use in-distribution predictive error for certain features to predict out-of-distribution sensitivity to changes in the distribution of those features. |
|
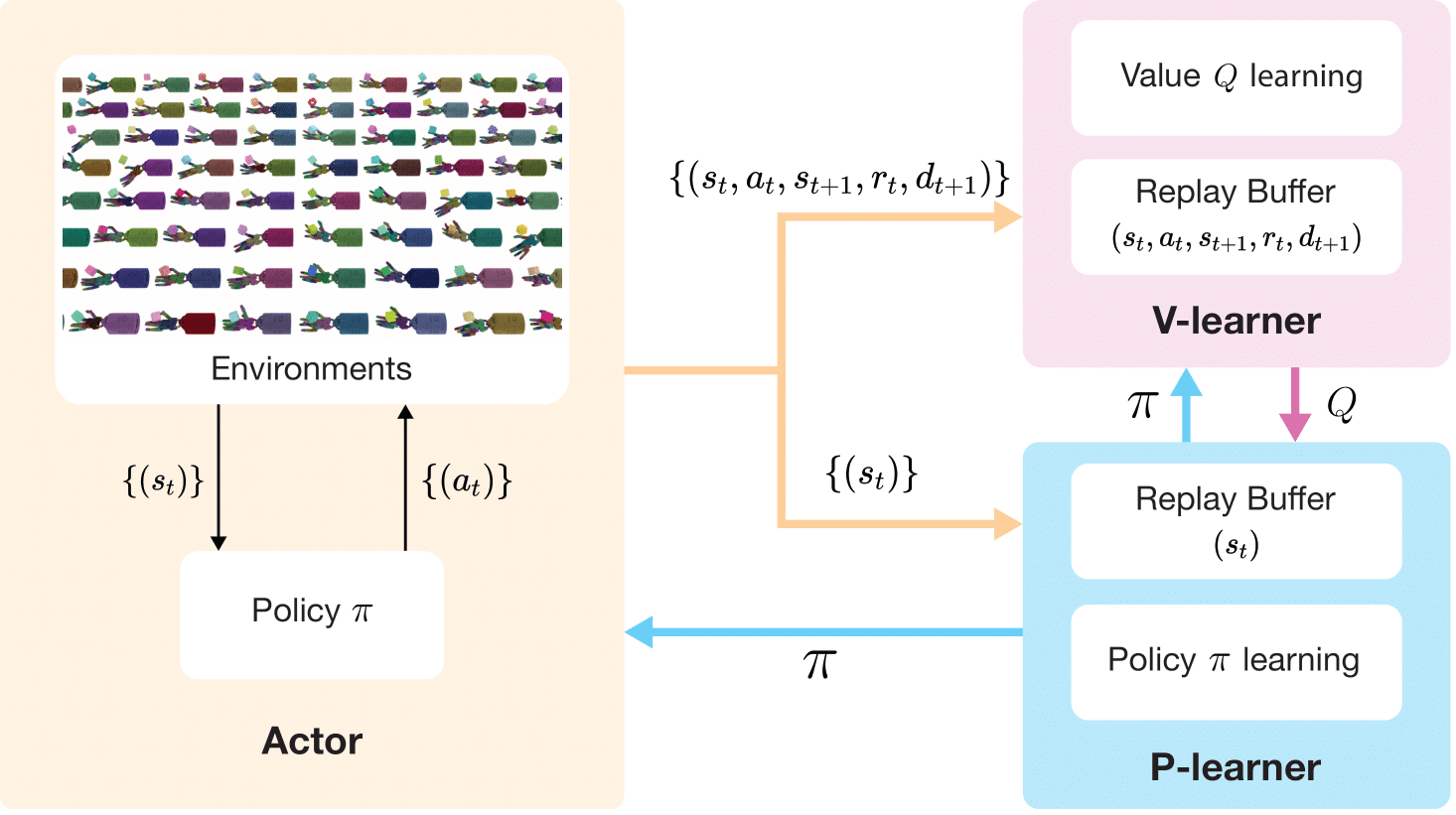
Zechu Li*, Tao Chen*, Zhang-Wei Hong, Anurag Ajay, Pulkit Agrawal (*Equal Contribution) ICML, 2023 openreview / bibtex / project page We present a novel parallel Q-learning framework that not only gains better sample efficiency but also reduces the training wall-clock time compared to PPO. Different from prior works on distributed off-policy learning, such as Apex, our framework is designed specifically for massively parallel GPU-based simulation and optimized to work on a single workstation. We demonstrate the capability of scaling up Q-learning methods to tens of thousands of parallel environments. |
|
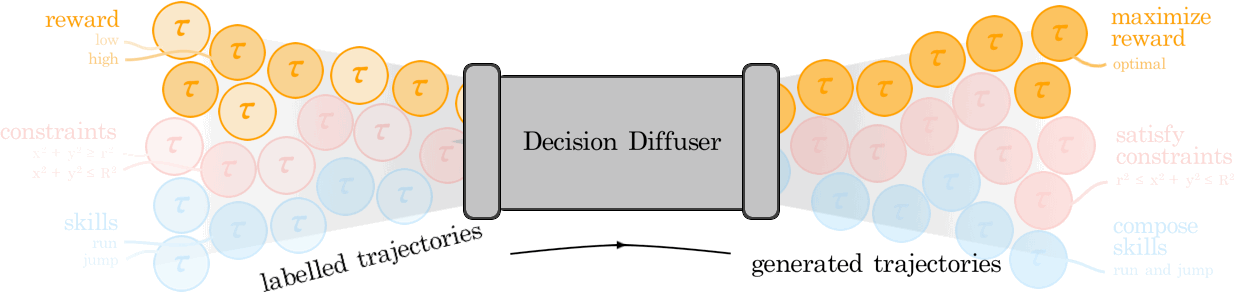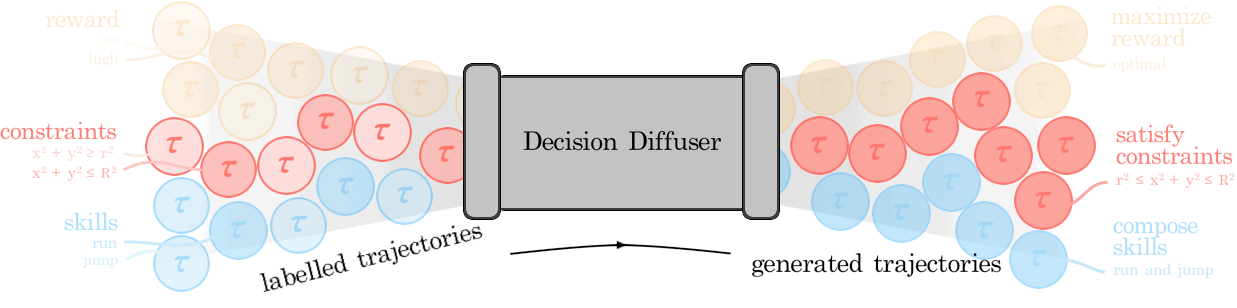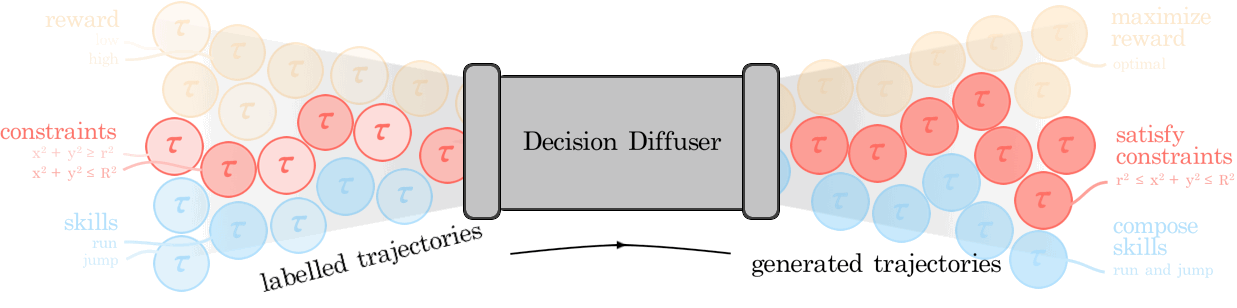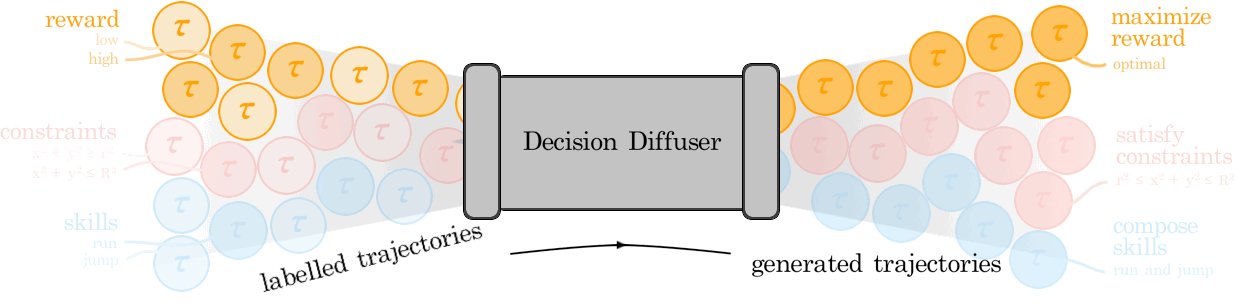
Anurag Ajay*, Yilun Du*, Abhi Gupta*, Josh Tenenbaum, Tommi Jaakkola, Pulkit Agrawal (*Equal Contribution) ICLR, 2023 (Oral, Top 5%) NeurIPS Foundational Model for Decision Making Workshop, 2022 (Oral) arXiv / bibtex / project page We view decision-making through the lens of conditional generative modeling. By modeling a policy as a return-conditional generative model, we eliminate many of the complexities of traditional offline RL. We further demonstrate the advantages of modeling policies as conditional generative models by considering two other conditioning variables: constraints and skills. Conditioning on a single constraint or skill during training leads to behaviors at test-time that can satisfy several constraints together or demonstrate a composition of skills. |
|
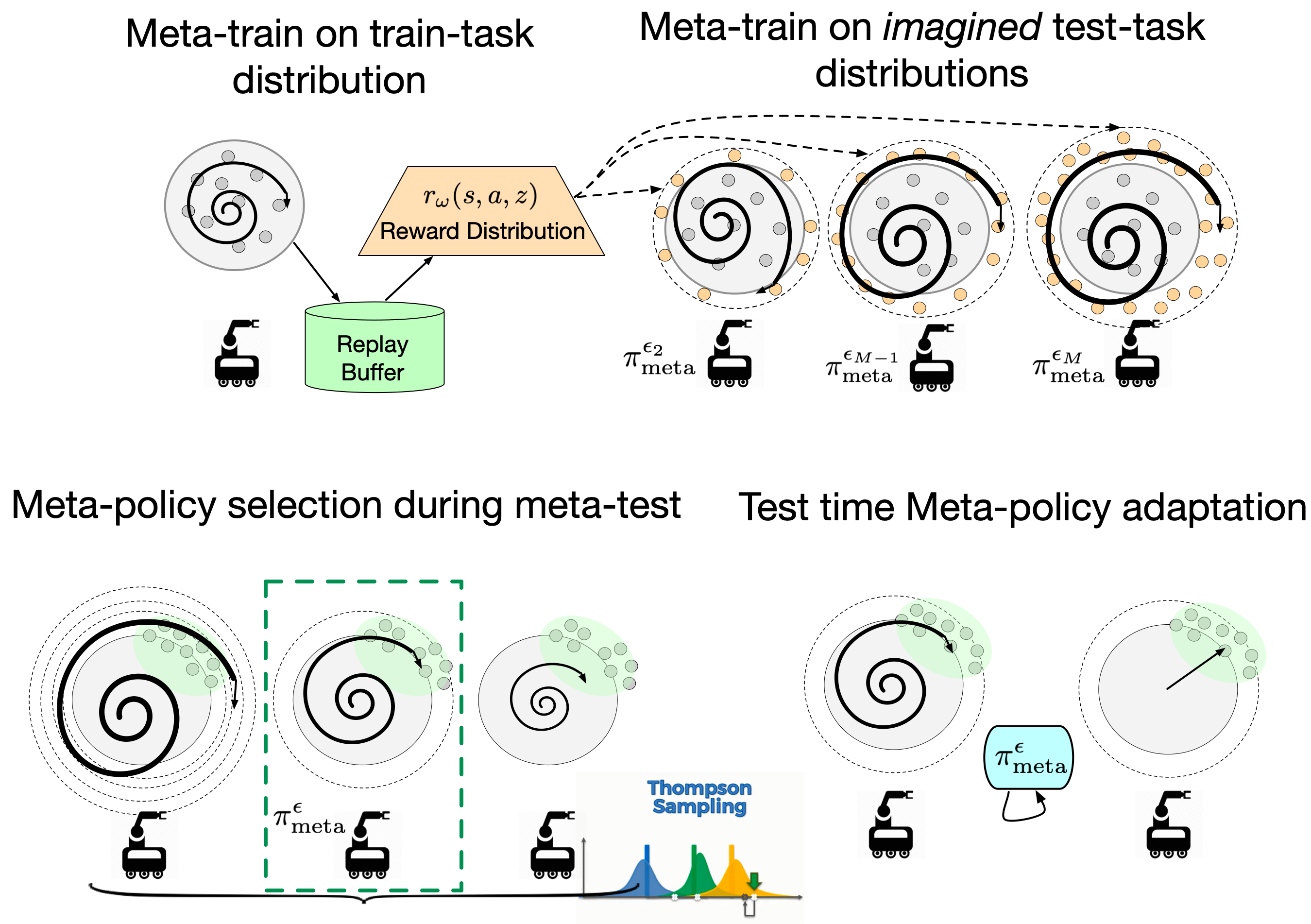
Anurag Ajay*, Abhishek Gupta*, Dibya Ghosh, Sergey Levine, Pulkit Agrawal (*Equal Contribution) NeurIPS, 2022 ICML Decision Awareness in Reinforcement Learning Workshop, 2022, ICML Principles of Distribution Shift Workshop, 2022, arXiv / bibtex / project page Our framework centers on an adaptive approach to distributional robustness that trains a population of meta-policies to be robust to varying levels of distribution shift. When evaluated on a potentially shifted test-time distribution of tasks, this allows us to choose the meta-policy with the most appropriate level of robustness, and use it to perform fast adaptation. We formally show how our framework allows for improved regret under distribution shift, and empirically show its efficacy on simulated robotics problems under a wide range of distribution shifts. |
|
Dibya Ghosh, Anurag Ajay, Pulkit Agrawal, Sergey Levine ICML, 2022 (ICML Long talk) arXiv / bibtex We propose that offline RL methods should instead be adaptive in the presence of uncertainty. We show that acting optimally in offline RL in a Bayesian sense involves solving an implicit POMDP. As a result, optimal policies for offline RL must be adaptive, depending not just on the current state but rather all the transitions seen so far during evaluation.We present a model-free algorithm for approximating this optimal adaptive policy, and demonstrate the efficacy of learning such adaptive policies in offline RL benchmarks. |
|
Ge Yang*, Anurag Ajay*, Pulkit Agrawal (*Equal Contribution) ICLR, 2022 openreview / bibtex / project page We re-examine off-policy reinforcement learning through the lens of kernel regression and propose to overcome such bias via a composite neural tangent kernel. With just a single line-change, our approach, the Fourier feature networks (FFN) produce state-of-the-art performance on challenging continuous control domains with only a fraction of the compute. Faster convergence and better off-policy stability also make it possible to remove the target network without suffering catastrophic divergences, which further reduces TD(0)’s bias to overestimate the value. |

|
Anurag Ajay*, Ge Yang*, Ofir Nachum, Pulkit Agrawal (*Equal Contribution) ICML Reinforcement Learning for Real Life Workshop, 2021 link / bibtex We use procedurally generated video games to empirically investigate several hypotheses to explain the lack of transfer. We also show that simple auxiliary tasks can improve the generalization of policies. Contrary to the belief that policy adaptation to new levels requires full policy finetuning, we find that visual features transfer across levels, and only the parameters, that use these visual features to predict actions, require finetuning. |

|
Anurag Ajay, Aviral Kumar, Pulkit Agrawal, Sergey Levine, Ofir Nachum ICLR, 2021 arXiv / bibtex / project page When presented with offline data composed of a variety of behaviors, an effective way to leverage this data is to extract a continuous space of recurring and temporally extended primitive behaviors before using these primitives for downstream task learning. Primitives extracted in this way serve two purposes: they delineate the behaviors that are supported by the data from those that are not, making them useful for avoiding distributional shift in offline RL; and they provide a degree of temporal abstraction, which reduces the effective horizon yielding better learning in theory, and improved offline RL in practice. |
|
Anurag Ajay, Pulkit Agrawal, ICML Inductive Biases, Invariances and Generalization in RL (BIG) Workshop, 2020 We learn a latent space for past useful action trajectories using an autoencoding model and explore in the learned space which improves performance in the context of transfer learning across tasks and in multi-task reinforcement learning. |
|
Nima Fazeli, Anurag Ajay, Alberto Rodriguez ICRA, 2020 arXiv / bibtex We propose a self-supervised approach to learning residual models for rigid-body simulators that exploits corrections of contact models to refine predictive performance and propagate uncertainty. |

|
Tom Silver*, Rohan Chitnis*, Anurag Ajay, Leslie Kaelbling, Josh Tenenbaum AAAI GenPlan Workshop, 2020 We learn lifted, goal-conditioned policies and use STRIPS planning with learned operator descriptions to solve a large suite of unseen test tasks. |
|
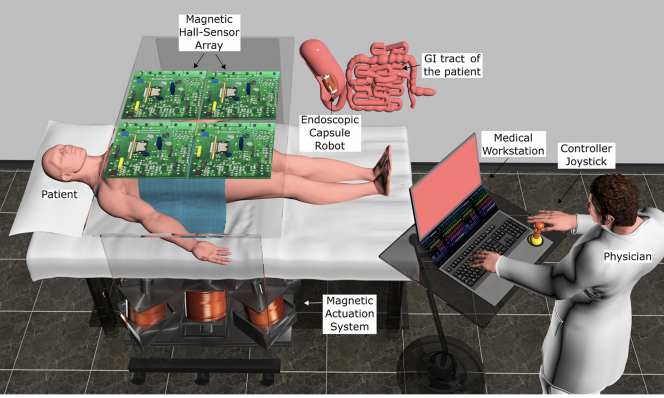
Mehmet Turan, Yasin Almalioglu, Hunter Gilbert, Faisal Mahmood, Nicholas Durr, Helder Araujo, Alp Eren Sarı, Anurag Ajay, Metin Sitti IEEE RAL, 2019 paper / bibtex We use deep reinforcement learning algorithms for controlling endoscopic capsule robots |
|
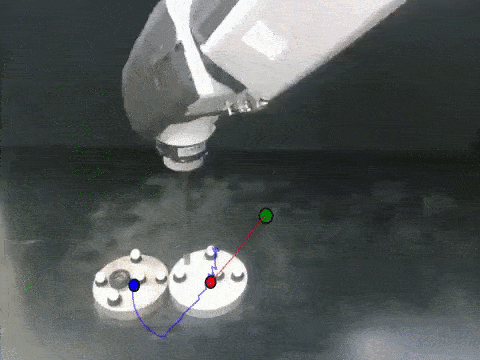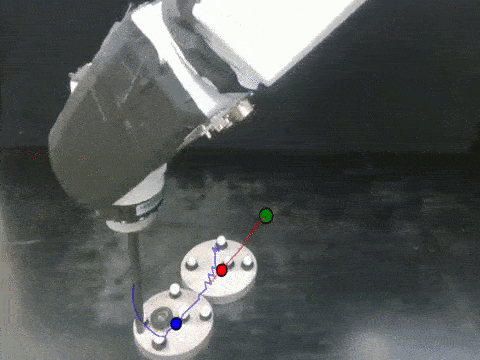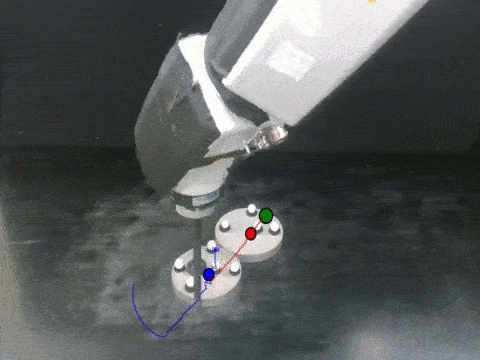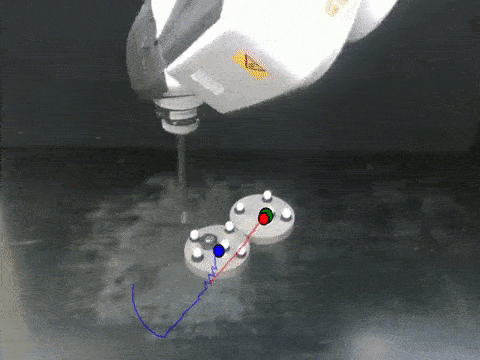
Anurag Ajay, Maria Bauza, Jiajun Wu, Nima Fazeli, Josh Tenenbaum, Alberto Rodriguez, Leslie Kaelbling ICRA, 2019 arXiv / bibtex / project page We propose a hybrid dynamics model, simulator-augmented interaction networks (SAIN), combining a physics engine with an object-based neural network for dynamics modeling. Compared with existing models that are purely analytical or purely data-driven, our hybrid model captures the dynamics of interacting objects in a more accurate and data-efficient manner. |
|
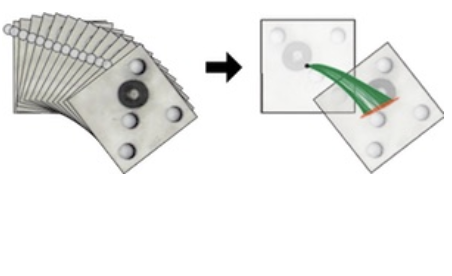
Anurag Ajay, Jiajun Wu, Nima Fazeli, Maria Bauza, Leslie Kaelbling, Josh Tenenbaum, Alberto Rodriguez IROS, 2018 (Best Paper on Cognitive Robotics) arXiv / bibtex / project page Combining symbolic, deterministic simulators with learnable, stochastic neural nets provides us with expressiveness, efficiency, and generalizability simultaneously. Our model outperforms both purely analytical and purely learned simulators consistently on real, standard benchmarks. |

|
William Montgomery*, Anurag Ajay*, Chelsea Finn, Pieter Abbeel, Sergey Levine ICRA, 2017 arXiv / bibtex / project page We present a new guided policy search algorithm that allows the method to be used in domains where the initial conditions are stochastic, which makes the method more applicable to general reinforcement learning problems and improves generalization performance in our robotic manipulation experiments. |

|
Tuomas Haarnoja, Anurag Ajay, Sergey Levine, Pieter Abbeel NIPS, 2016 arXiv / bibtex We represent kalman filter as a computational graph and use it in place of recurrent neural networks for data-efficient end to end visual state estimation. |
|
|
|
Reviewer for IROS, IEEE-RAL, ICRA, ICML, NeurIPS, ICLR, CoRL
TA for 6.884 (Computational Sensorimotor Learning) Spring 2020 GSI for CS 189 (Introduction to Machine Learning) Fall 2016, Spring 2017 |
|
|